Why I am (still) finding secrets in your code
Despite the widespread availability of secret scanning tools, thousands of sensitive credentials continue to be exposed in popular open source ecosystems, a security blind spot that sparked my curiosity and one that led me to hunt for secrets in both commonly understood risk areas and find some new attack surface with some surprising results.
Phase 1 Results
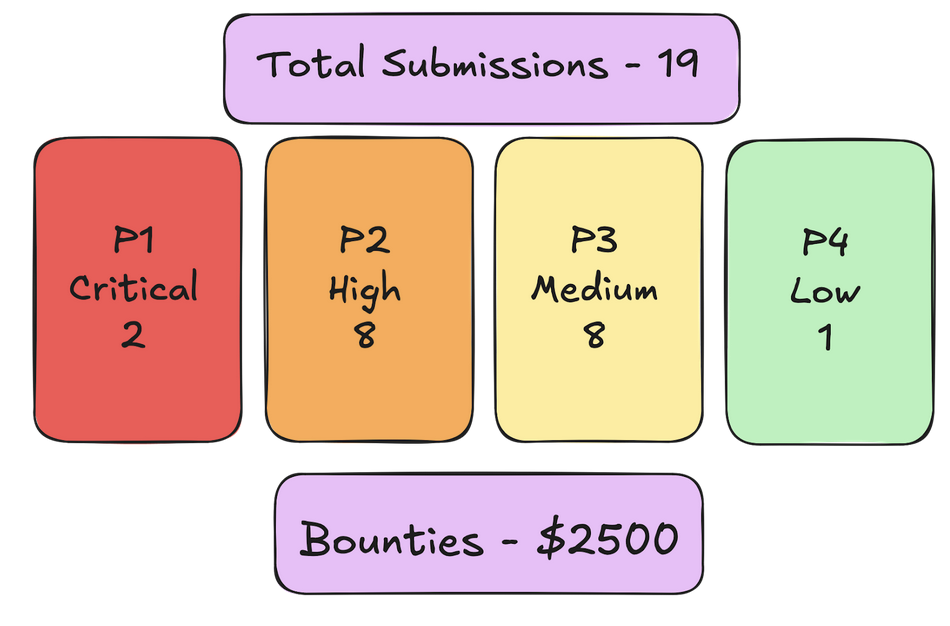
Phase 1 of my research delivered some interesting results: 19 security reports submitted across hosted and self-hosted bug bounty and vulnerable disclosure programs yielding $2500 in rewards. The submissions included:
- P1 - 2 (Intigriti)
- P2 - 8 (Hackerone, Bugcrowd, self hosted)
- P3 - 8 (Hackerone, Bugcrowd, self hosted)
- P4 - 1 (Hackerone)
For Phase 1, in total over 43,906 verified secrets were discovered across the PyPi and NPM ecosystems. With over 4.1m packages scanned around 1% of packages published to these registries contained a verified secret.
Of these 43,906 verified secrets 23.8% of them were discovered in a package that belonged to an organisation whilst 75.8% of them belonged to packages published by personal email addresses like gmail, yahoo, proton etc.

Discovering New (Old) Attack Surface
Curiosity really led me down this rabbit hole, whilst looking into some malicious NPM packages at work, you know the crypto miner classics that are posted daily I noticed that there were some hard coded API keys in the packages source code.
As I sat there and looked at the hard coded CapSolver API token I had a thought, has anyone ever scanned the entire NPM ecosystem before? I did a quick follow up google search and couldn't find much and after a quick look at the NPM homepage that shows the total packages published I figured why, 3.4m packages and counting. I decided to give it a go, at the very least it would keep me busy for a few days and I might even get a blog post out of it, win or fail.
Further down the track this initial curiosity would lead me to implementing an automated scanner framework for Docker, PyPi, Github and NPM, earning over $20,000 and in total 30+ vulnerabilities reported and counting.
Trufflehog
Secret scanning is well-established in the security landscape, with numerous open source tools like Trufflehog, Gitleaks, Whispers and detect-secrets available that can identify and remediate leaked credentials across a wide range of services.
These tools allow you to automatically scan a wide range of ecosystems that your organization might have a footprint in, for example Github, Gitlab, Confluence and Slack. Most of these tools are easily implemented in your CI/CD pipelines as well making them a great security addition to your deployment process.
For my research I decided to utilise Trufflehog due to its ease of use, breadth of scope and ability to natively validate secrets. Trufflehog has over 800 in built detectors and can be easily customized to suit your needs, you can check it out here.
Trufflehog is also easily implemented in CI/CD pipelines via an action so that any commits you make are automatically scanned before getting merged into your code base. The enterprise version also gives you access to continuous monitoring of your ecosystems so that you are alerted in real time when leaked secrets are detected.
In fact after researchers discovered over 1500+ exposed credentials in Hugging Face (lasso research) the organisation partnered with Trufflehog to implement secret scanning natively as part of any git commits happening on the platform (Hugging Face docs).
Prior to Hugging Face partnering with Trufflehog I created a monitoring automation that would receive webhook events from Hugging Face when a commit occurred in different organisations. You can read more about that research here.
Phase 1 Scanner Architecture
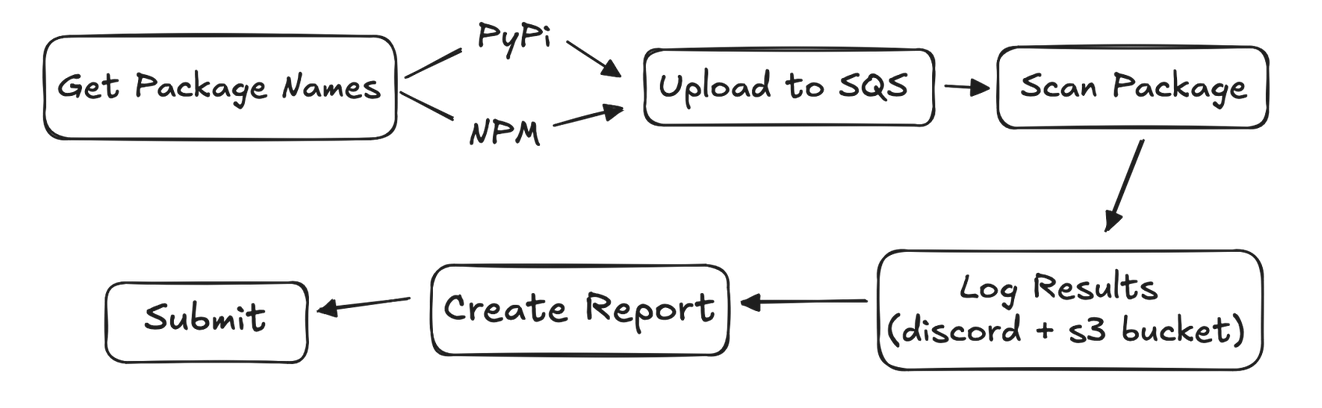
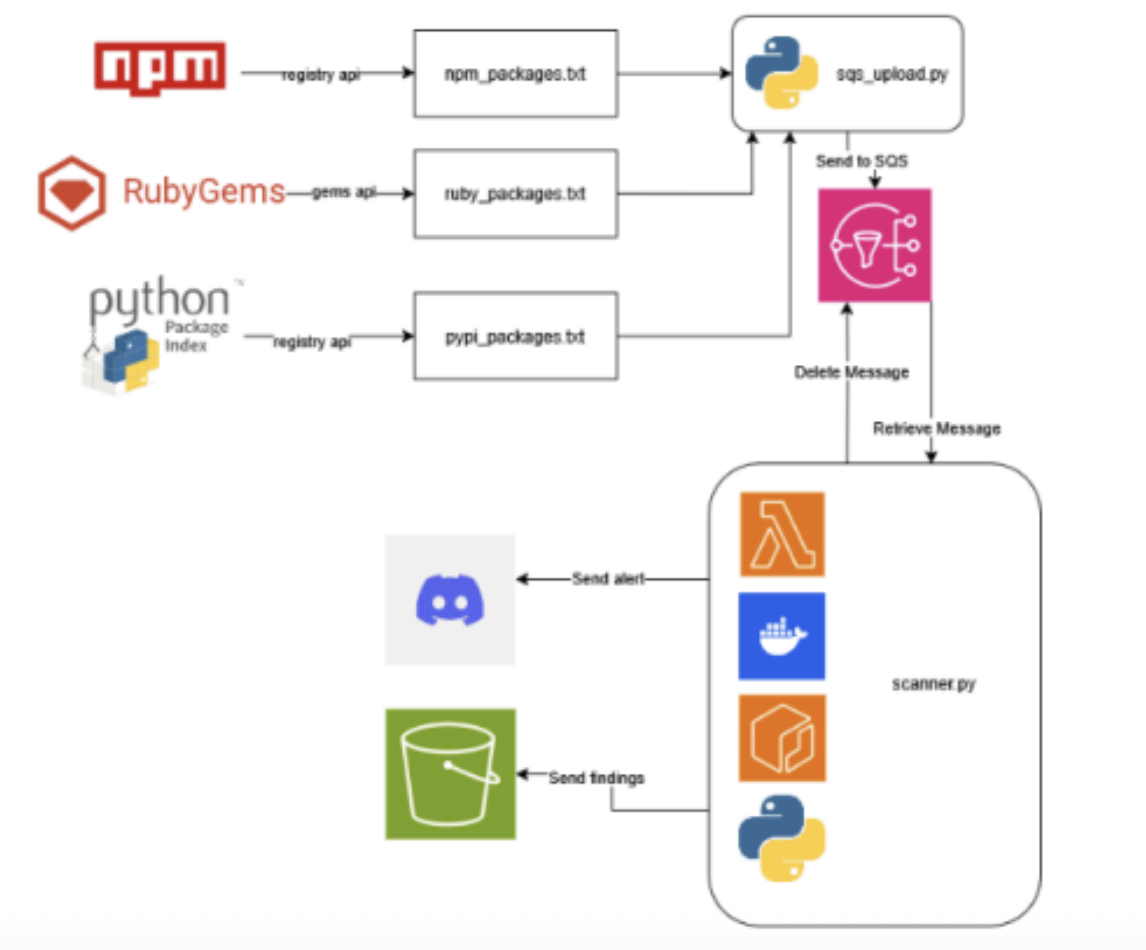
The flow for this scanner is very basic, we statically generate the NPM, RubyGems and PyPi package.txt file using the respective registries API. From there we upload those packages to an AWS SQS and the scanner.py code retrieves each package, downloads the package and scan's it using Trufflehog, finally it deletes the package and message from the SQS and outputs the results to an S3 bucket and discord server.
Challenges
In my proof of concept stage I just wanted to confirm how hard it would be to get Trufflehog set up inside a lambda environment. Since Trufflehog doesn't natively scan package managers I would have to use the --filesystem flag to scan the package code.
Despite AWS Lambda's ephemeral nature, I ran into a few issues with disk storage persisting across invocations. This persistence meant package code accumulated over time, causing storage to fill after 10-20 packages and resulting in the Lambda function failing.
As a fix I implemented a simple rm -rf of the package directory after the scan was taking place, this worked except I was still finding the Lambda was still erroring out after 40-50 packages. After a few hours of troubleshooting I found that the Lambda was actually creating a weird file after each package was downloaded, this file was not part of the package code and to be honest I am not 100% sure what it was doing. If you happen to know please reach out. I'd love to know.
I ended up just taking the nuclear option and doing a shutil.rmtree on the entire /tmp directory to ensure we were removing everything.
This worked and I finally had my proof of concept that I could programmatically run through each package, scan it, remove it from the SQS and then log results to both discord and an S3 bucket.
The next 2 issues were time and cost, one of the main reasons I chose to use an AWS Lambda for this research was so that I could increase the concurrency to improve the rate at which we processed packages. This is important as at 1 concurrent Lambda invocation it would take ~50 days to scan 4.18m packages at 1 second a package. Obviously 1 second a package is very quick and I would more likely be expecting 4-5 seconds a package, which is ~200 days.
I began experimenting with the concurrency of the Lambda and found that even 200 concurrency was too slow for my liking. I was also going away camping for the weekend, it was currently Friday morning and I wanted to be able to triage the findings the following week.
So.. I pumped the concurrency to 1000 and decided to just go for it. After an hour of running I found I was processing around 150k packages an hour which was really good and meant I should be able to do them all by the end of the weekend and I could triage the next week.
In terms of cost, at the end of the 4.18m packages I ended up with a $475 USD bill but luckily had $300 of AWS credits lying around that had to be used that month anyway, overall not too bad but this definitely meant for future runs I would need something most sustainable and cost effective.
In total the scan took a total of 9 days to complete, this included troubleshooting and testing. With around 4.1m packages scanned the final AWS bill ended up being around $475, luckily I had $300 worth of AWS credits that was to be used at the end of Feb so the total cost to me was approx $175. Although successful this demonstrated to me that I would need a much more cost effective solution if I wanted to continue the scanning.
Refining The Approach
Phase 1 results revealed systematic problems with how organisations manage secrets across open source ecosystems. It was after submitting the final results from the phase 1 scan I spoke with a good friend of mine (@aussinfosec) who is a veteran in the bug bounty space and we decided to team up to refine the approach.
Targeting Bounties
Together we decided to shift the approach to look at organisations that had Bug Bounty Programs and Vulnerable Disclosure Program. This would dramatically cut down on the packages scanned as we would be removing mostly personal packages which is a very large proportion of these package managers.
If we could filter out these packages we should be able to only scan packages that we knew had bounty programs and therefore maximize our potential earnings whilst minimizing time spent triaging and scanning.
For identifying relevant targets, we needed a dynamic method to obtain bounty program domains for our scanners. I opted to use two existing GitHub repositories that did this for public programs across Hackerone, Bugcrowd, Intigriti & Yeswehack (bounty-targets-data and h1domains). To retrieve private programs I also created a custom script to retrieve private Hackerone program domains and Google's Android repositories from this source (android.googlesource.com).
Continuous Monitoring
We also determined that since we had basically scanned every package on NPM and PyPi (latest versions only) we should work out a way that we can continuously monitor and scan for packages being updated and published to the registry.
So with this plan in mind, @aussinfosec kindly offered his NuC up as a server for us to use for our scanners, this would also lessen the cost considerably. We planned to focus on these open source ecosystems:
- Docker
- NPM
- PyPi
- Github
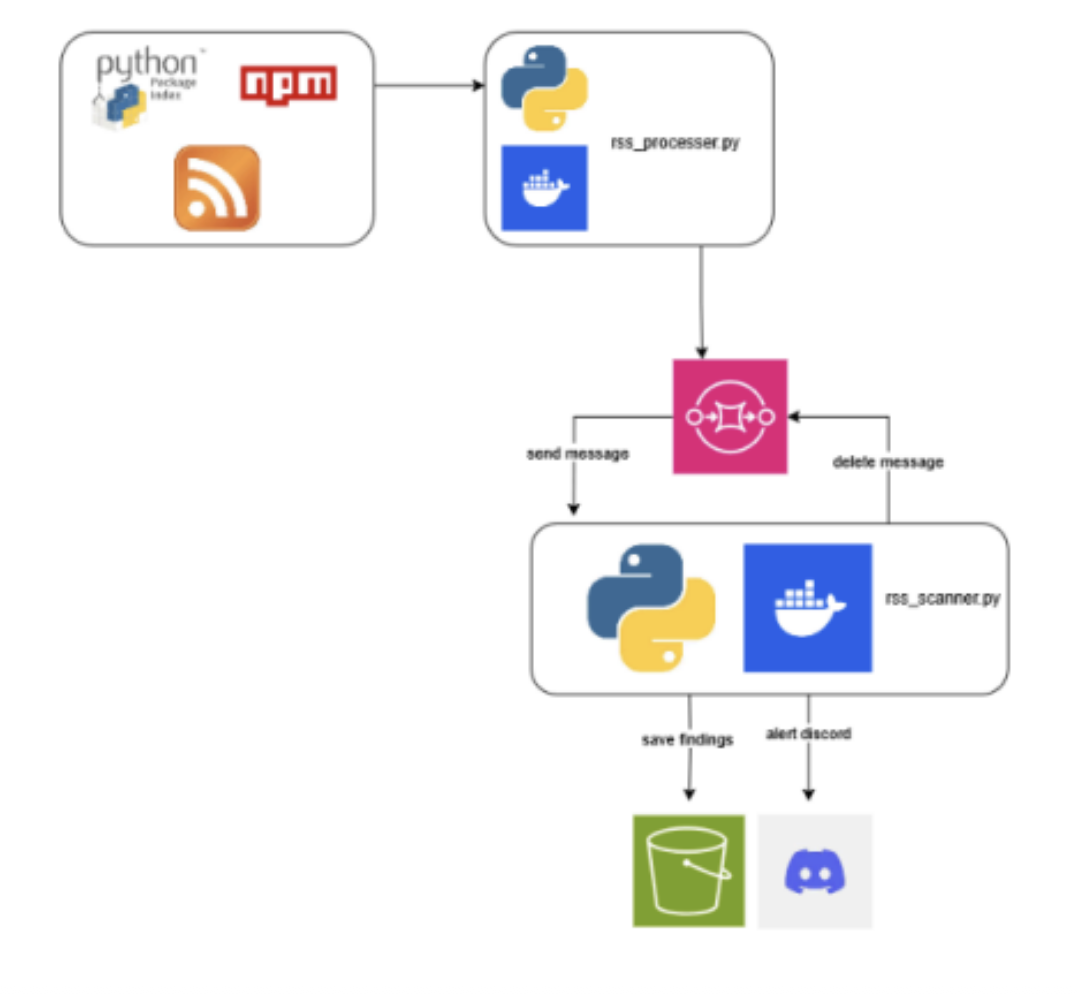
We implemented continuous monitoring of PyPi and NPM repositories by utilizing their respective RSS feeds (PyPi feeds and NPM feeds). These feeds provide notifications about recently published and updated packages. We adapted our phase 1 script to parse these RSS feeds, specifically filtering for packages related to our bounty target organizations. Identified packages were then sent to a dedicated SQS queue, where our scanners continuously monitored and processed them.
The reason I chose to have a rss_processer script was so we wouldn't be missing out on packages if the scanner was taking too long to process packages, this way we separate them and the processor simply handles sending the packages to the SQS queue and the scanner can focus on scanning.
Database Implementation
Developing a comprehensive scanner for an organization's entire NPM, PyPi, Docker, and GitHub presence requires additional engineering work. The primary challenge lies in the limitations of the package registries' search capabilities. Both NPM and PyPi APIs restrict searches to author names or package names only, with no direct method to query by domain.
NPM documentation: REGISTRY-API.md
PyPi documentation: JSON API
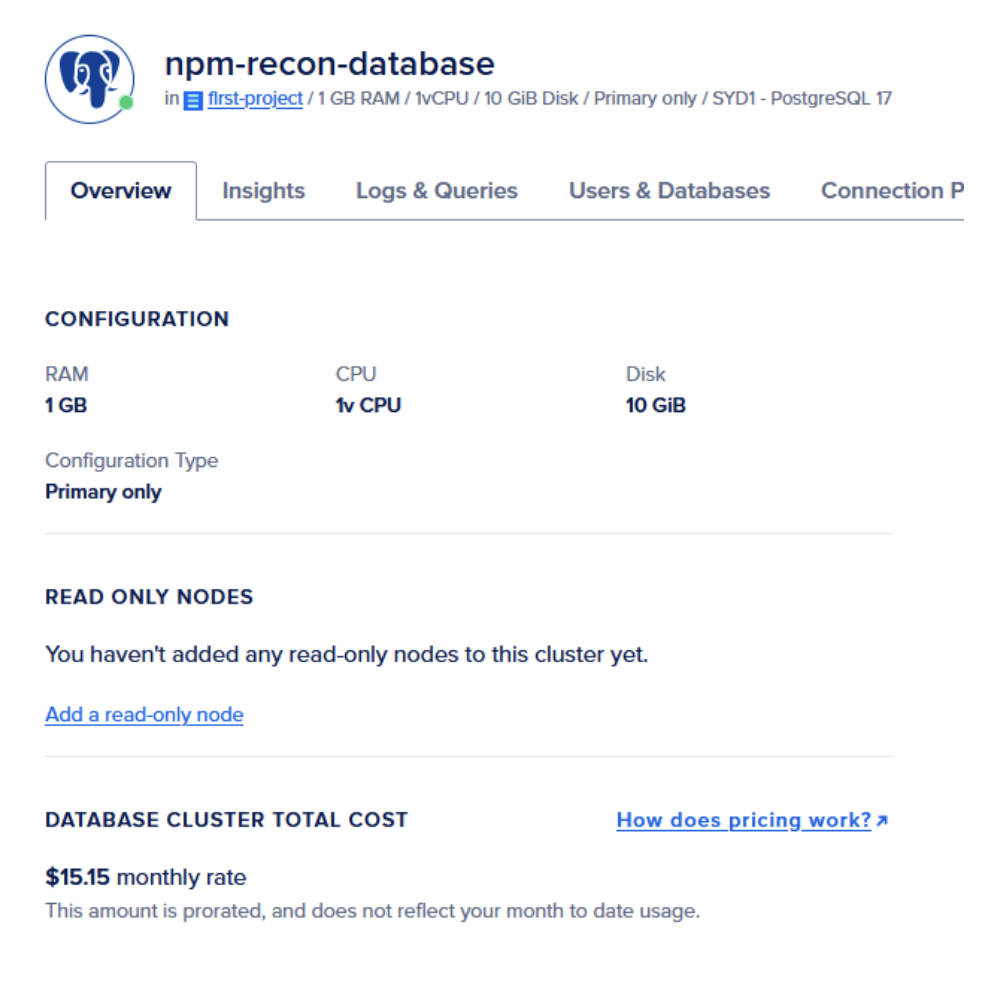
To efficiently track scanned packages and their versions, I developed a database solution that leverages the immutability of PyPi and NPM package versions. Once a specific version is scanned and verified to be free of secrets, it doesn't require rescanning since package registries prevent modifications to published versions.
My approach involved creating a custom PostgreSQL database on Digital Ocean to index both PyPi and NPM registries. To manage the database size and processing requirements, I implemented filters to exclude personal domains. This solution has proven reliable and cost-effective at approximately $15 per month for hosting with minimal processing issues.
Once I had the data stored into my database I needed to modify the phase 1 scanners so that instead of using an SQS we simply query that database for a given domain and loop through these domains outputting the results to an S3 bucket and discord.
Logging & Alerting
The reason I chose to use an S3 bucket and discord for logging is just a redundancy. The S3 bucket allows me to query the data later on and the discord logging is easily viewable from any device so if I am out I can still check events as they come in.
I used discord to log errors too and this worked surprisingly well, for each ecosystem I have a verified channel and error logging channel.
The alerts would come in structured so we could easily understand everything we needed to submit a report including the package name, version, maintainers, file location, detector and the secret.

Phase 2 Results
It's hard to tell exactly how many packages and versions were scanned as a result of the Phase 2 scanning and right now it's still happening but at the moment we are processing around 11,000 unique domains, 100 docker orgs and 200 Github repositories.
6 of these submissions were submitted to self hosted programs that do not offer bounties.
- P1 (Critical or Exceptional) - 2 (Intigriti)
- P2 (High) - 6 (Hackerone, Bugcrowd, self hosted)
- P3 (Medium) - 7 (Hackerone, Bugcrowd, self hosted)
- P5 (Low) - 1 (Hackerone)
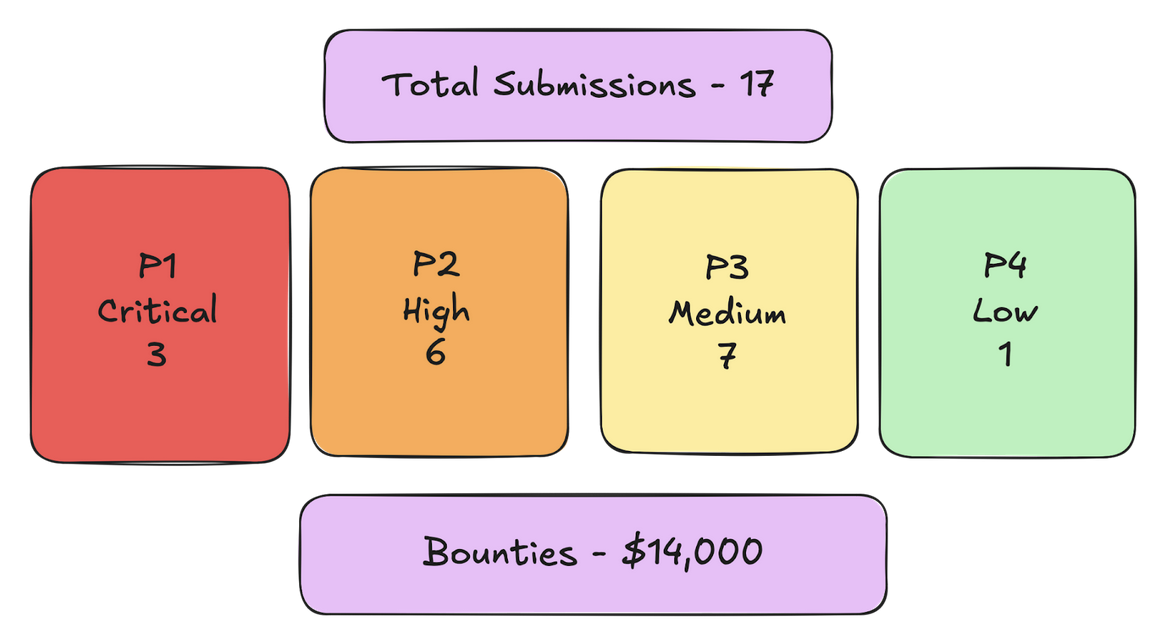
In total these submissions yielded $20,000 (and counting) whilst resulting in overall fewer results due to the scoped scan.
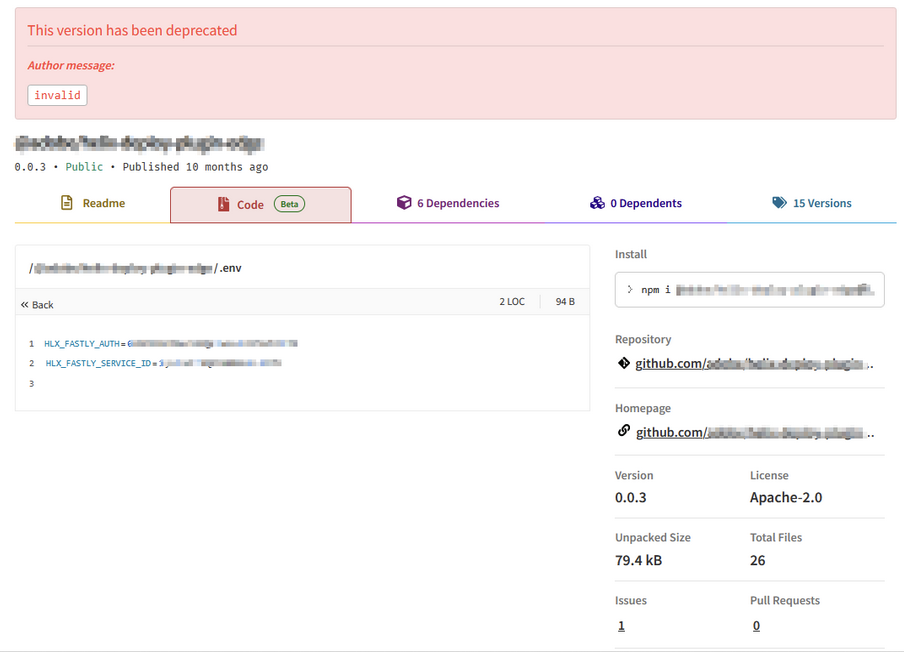
The phase 2 results offered some insight into the root cause of these exposed credentials. In one of the reports an exposed fastly API token was found in a deprecated version of an active NPM package that was linked to a GitHub repository. The affected versions of this package were 0.1.0, 0.2.0 and 0.3.0 whilst the GitHub repository began at version 1.0.0 and whilst these deprecated versions were no longer available to install the code was still visible via the NPM website and downloadable via the API.
From version 1.0.0 onward, the package was published automatically through a CI/CD pipeline that also managed version updates. While the organization may have implemented secret scanning tools, these would typically only monitor the GitHub repository, missing the deprecated versions containing exposed secrets that existed solely in the package registry.
We encountered similar patterns in other cases, including a 7-year-old MongoDB credential exposed in a test environment. The organization acknowledged they were unaware this secret existed in the package. Once again, the secret appeared in a package version that had no corresponding version in the associated GitHub repository, bypassing any CI/CD pipeline security measures.
These findings highlight a critical visibility gap organizations face with registry packages. Many are simply unaware of certain versions of their packages, particularly those published early in development before formal CI/CD processes were established. This creates a significant blind spot where secrets published by developers during initial development phases circumvent security mechanisms that would otherwise catch such exposures.
Case Studies
I would like to thank EA Games and Schibsted Marketplace for allowing me to publicly disclose some of the vulnerabilities that I submitted to them via this research.
Exceptional Finding - Exposed Github PAT
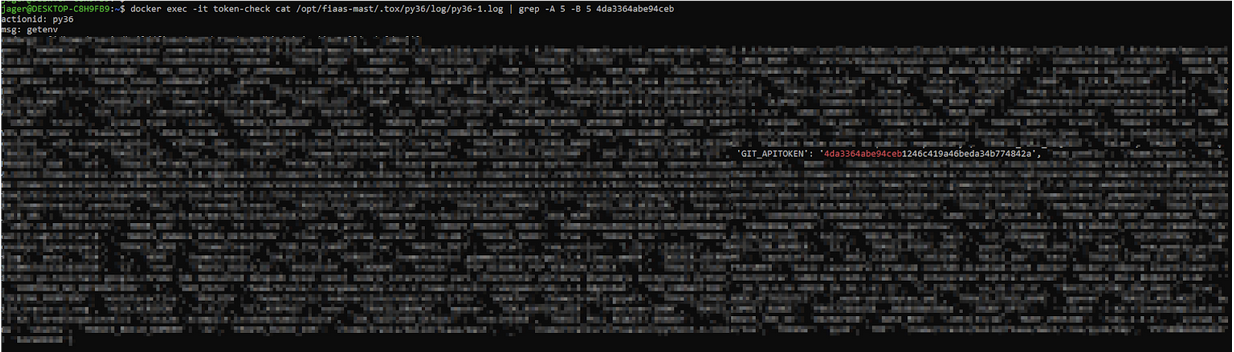
Firstly, using a simple Google dork, I discovered they had a Docker organization for their open source repositories. I added this Docker org to the main domains list for our Docker scanner, which then ran Trufflehog over each image and version under the FIAAS organization.
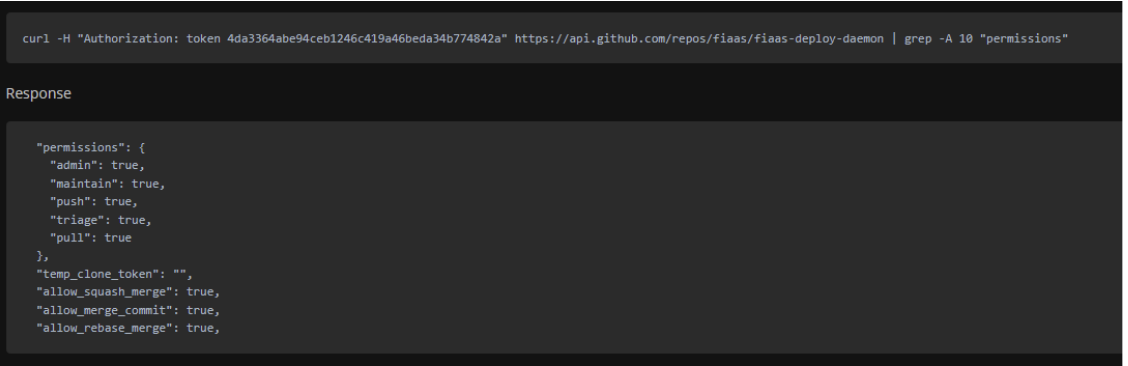
The scanner hit paydirt: Trufflehog identified an exposed Personal Access Token (PAT) in an image published back in 2019 (docker hub link).

This secret was inadvertently captured in Python build logs due to a known vulnerability in the Docker version they were running at the time (Docker release notes).
What made this finding particularly alarming was that this token had been exposed for nearly 6 years with full administrative access to their open source repositories. In the wrong hands, this could have facilitated a devastating supply chain attack. An adversary could have silently injected malicious code into their widely-used open source packages, potentially compromising thousands of downstream systems and organizations.

Exposed AWS Credentials in Contractor Package
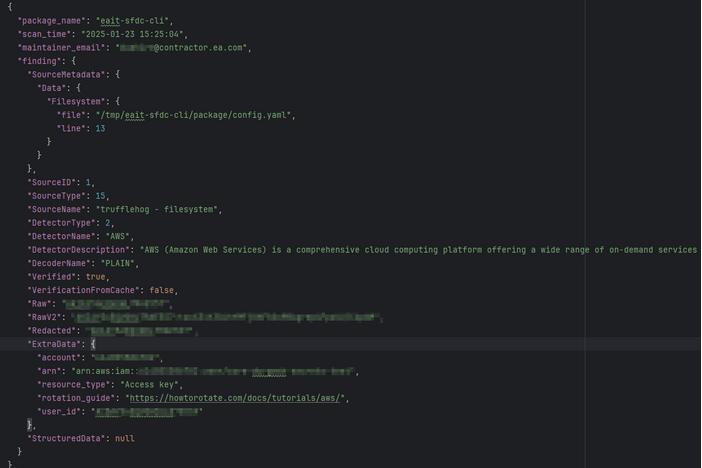
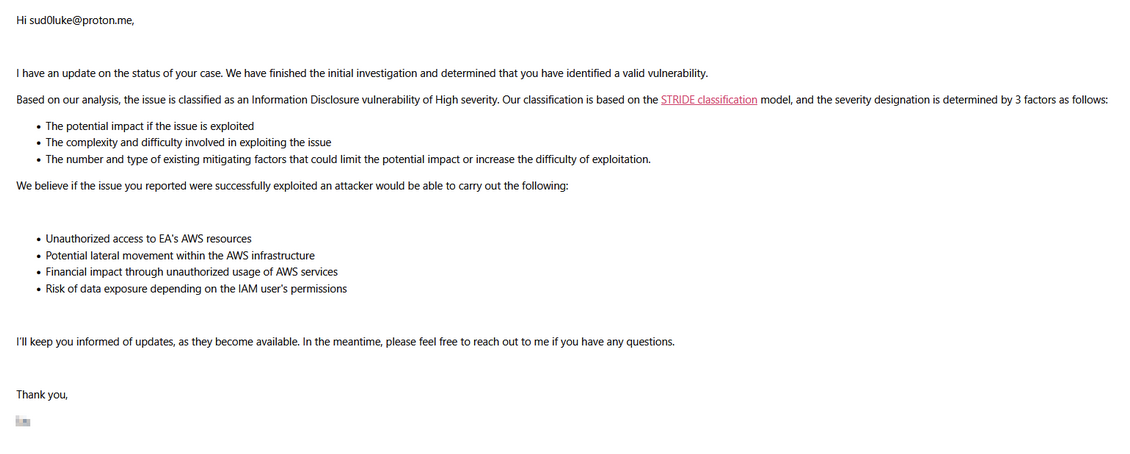
A set of exposed AWS Credentials were discovered hard coded in an NPM package that had access to an internal Electronic Arts (EA) AWS instance. These credentials were found in a config.yaml file in the latest published version of the eait-sfdc-sli package. These credentials provided programmatic access with permissions allowing read / write access to an internal S3 bucket.
The package maintainers domain was @contractor.ea.com a subdomain of EA, I assume this is used by contractors of EA. After looking at the source code it appeared this package was used as a salesforce cli integration that was being utilised in their development / testing environment. EA confirmed that these were not used in production.
The package was published 6 months ago with no GitHub repository linked and minimal updates, it also had around 2-3 average downloads per day so I assume this was only used by the contractor. EA confirmed that after investigating the logs to their AWS instances no unexpected / unauthorised access had been found.
I discovered these credentials during the phase 1 scan and responsibly disclosed them to EA's security team. After reporting the bug to the EA games security team I received a notification that they were looking into it, shortly after this the credentials were revoked and the package was removed.
The EA security team explained that they investigated the impact of the exposed credentials thoroughly and determined it to be a High severity issue with exploitation potentially leading to:
- Unauthorized access to EA's AWS resources
- Potential lateral movement within the AWS infrastructure
- Financial impact through unauthorized usage of AWS services
- Risk of data exposure depending on the IAM user's permissions
These credentials were found in the latest version of an open source ecosystem and were a consequence of human error rather than an issue with the proprietary software used to build the artifact.
These examples could have both been mitigated with some form of secret scanning whether in a CI/CD pipeline upon publication like the EA NPM example or with deep scanning of open source versions like the Schibsted issue.
What Can You Do About It?
The most effective way to remediate secret leakage for any organisation is to implement robust CI/CD pipelines with pre-commit scanning for all code destined for public repositories and ecosystems (and honestly even for code that isn't). This is a much more proactive approach which ensures you are mitigating at the source and not reactively revoking or scanning for tokens.
Within CI/CD pipelines, pre-commit hooks or actions utilizing Trufflehog can scan pull requests for potential secrets before they're merged. But what about existing code that's already committed? And how can you determine your organization's complete footprint across these ecosystems?
Using the database indexing code, you can effectively replicate the NPM and PyPi registries, focusing only on specific maintainers and authors associated with your domains of interest. This approach works equally well for bug bounty hunters, red teams, or blue teams— the domain filtering is entirely customizable.
The scanner code can be used to query your database by a given JSON file of domains and will scan every package under that domain and scan every version. This is a great way to ensure that as an organisation you can 1. accurately determine what's what in NPM and PyPi and 2. find any leaked secrets that you might not know about.
The scanner code can query the registry database using a simple JSON file of domains, systematically examining every package and version associated with those domains. This approach serves multiple security functions:
- For Blue Teams: Accurately map your organization's footprint across NPM and PyPi ecosystems, discover shadow IT packages, and identify leaked secrets before attackers do.
- For Red Teams: Quickly identify an organization's complete package ecosystem during security assessments, uncovering potential attack vectors through exposed credentials.
- For Bounty Hunters: Efficiently scan target organizations for exposed secrets across their entire package ecosystem, focusing only on domains with active bounty programs to maximize ROI.
I'm open-sourcing these tools because there's a serious security gap: developers are frequently uploading organizational secrets without realizing it, and often without the organization's knowledge. The absence of built-in secret scanning in NPM and PyPi's publishing pipelines enables this problem to persist unchecked.
Package registries like NPM and PyPi should follow Hugging Face's example by implementing automated secret scanning during package publication. Even a simple warning system would significantly reduce exposure by alerting developers before sensitive credentials reach public repositories, allowing them to take corrective action.
A dangerous misconception exists that packages in PyPi or NPM linked to GitHub repositories contain identical code. This isn't necessarily true—any repository can be linked to a package regardless of content correlation. Organizations often develop and publish packages before linking them to GitHub or implementing automated publishing pipelines, meaning only the latest versions might match the repository code while earlier versions remain unverified.
It's important to acknowledge that not all organizations have the resources to implement robust CI/CD pipelines, or the ability to fully control developer publishing practices. While education for developers remains valuable, this scanning framework offers an accessible, low-cost alternative to ensure you're not unknowingly exposing sensitive credentials across public package ecosystems.
If you have any questions please reach out to me [email protected] or if you'd like to contribute please do.